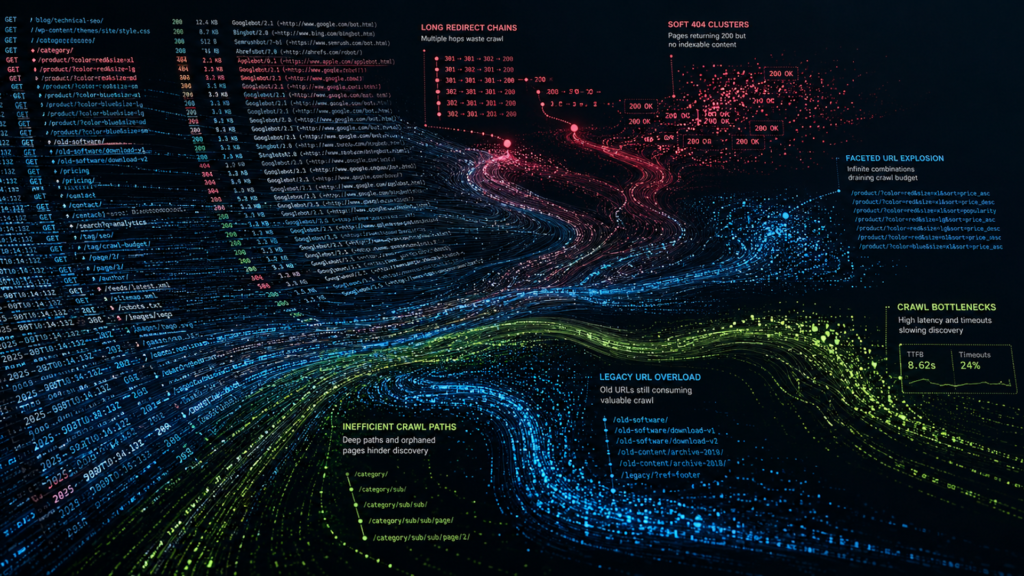

For large websites, server logs often reveal technical SEO problems long before rankings decline. They show how search engines crawl your site, where crawl budget gets wasted, how quickly servers respond, and whether important pages remain accessible.
Unlike Google Search Console, analytics platforms, and third-party crawlers, server logs capture every request search engines make to your infrastructure.
Yet many organizations never analyze them — missing one of the most valuable sources of technical SEO data available.
Many SEO teams rely on Google Search Console, Bing Webmaster Tools, third-party crawlers, and analytics platforms. Those tools help, but they all rely on data samples, delayed reporting, or simulated crawls.
Server logs capture direct interactions between crawlers and infrastructure. That distinction matters on websites with hundreds of thousands or millions of URLs.
A log file records every request processed by a server. For SEO purposes, the most useful entries come from crawlers such as Googlebot, Bingbot, GPTBot, Applebot, and other verified search engine bots.
Each request generates operational data, including the requested URL, response code, timestamp, user agent, and response timing. Over time, those records form a detailed crawl history.
Your customers search everywhere. Make sure your brand shows up.
The SEO toolkit you know, plus the AI visibility data you need.
Start Free Trial
Get started with

Hidden SEO issues in crawl data
Most technical SEO issues begin as crawl inefficiencies that gradually compound over time. A search engine crawler may:
- Request a page and receive an unexpected response.
- Encounter a category section that slows under heavy load.
- Follow redirect chains that expanded after a deployment.
In other cases, product pages disappear from inventory while still returning a 200 status code. These problems rarely occur as isolated incidents.
Search engines encounter them repeatedly across thousands or millions of crawl requests, creating patterns that can quietly erode crawl efficiency, indexing, and visibility.
Server logs expose those patterns clearly.
- On large ecommerce platforms, logs often show crawlers spending excessive time on filtered navigation URLs while strategic product pages receive limited recrawling.
- On publisher websites, crawlers sometimes revisit outdated archive paths more aggressively than newly updated content.
- SaaS platforms frequently expose staging environments or parameter-driven duplicate URLs through internal systems without realizing how heavily those URLs consume crawl activity.
Without logs, those problems remain hidden behind aggregate reporting.
Server logs also provide historical visibility. Unlike Google Search Console data, which expires over time, retained logs reveal crawl trends…
Source link
Disclaimer
We strive to uphold the highest ethical standards in all of our reporting and coverage. We blogs.grocliq.com want to be transparent with our readers about any potential conflicts of interest that may arise in our work. It’s possible that some of the investors we feature may have connections to other businesses, including competitors or companies we write about. However, we want to assure our readers that this will not have any impact on the integrity or impartiality of our reporting. We are committed to delivering accurate, unbiased news and information to our audience, and we will continue to uphold our ethics and principles in all of our work. Thank you for your trust and support.
Website Upgradation is going on for any glitch kindly connect at [email protected]



