This is all based on the Google leak and tallies up with my experience of content that does well in Discover over time. I have pulled out what I think are the most prominent Discover proxies and grouped them into what seems like the appropriate workflow.
Like a disgraced BBC employee, thoughts are my own.
TL;DR
- Your site needs to be seen as a “trusted source” with low SPAM, evaluated by proxies like publisher trust score, in order to be eligible.
- Discover is driven by a six-part pipeline, using good vs. bad clicks (long dwell time vs. pogo-sticking) and repeat visits to continuously score and re-score content quality.
- Fresh content gets an initial boost. Success hinges on a strong CTR and positive early-stage engagement (good clicks/shares from all channels count, not just Discover).
- Content that aligns with a user’s interests is prioritised. To optimize, focus on your areas of topical authority, use a compelling headline(s), be entity-driven, and use large (1200px+) images.
 Image Credit: Harry Clarkson-Bennett
Image Credit: Harry Clarkson-BennettI count 15 different proxies that Google uses to guide satiate the doomscrollers’ desperate need for quality content in the Discover feed. It’s not that different to how traditional Google search works.
But traditional search (a high-quality pull channel) is worlds apart from Discover. Audiences killing time on trains. At their in-laws. The toilet. Given they’re part of the same ecosystem, they’re bundled together into one monolithic entity.
And here’s how it works.
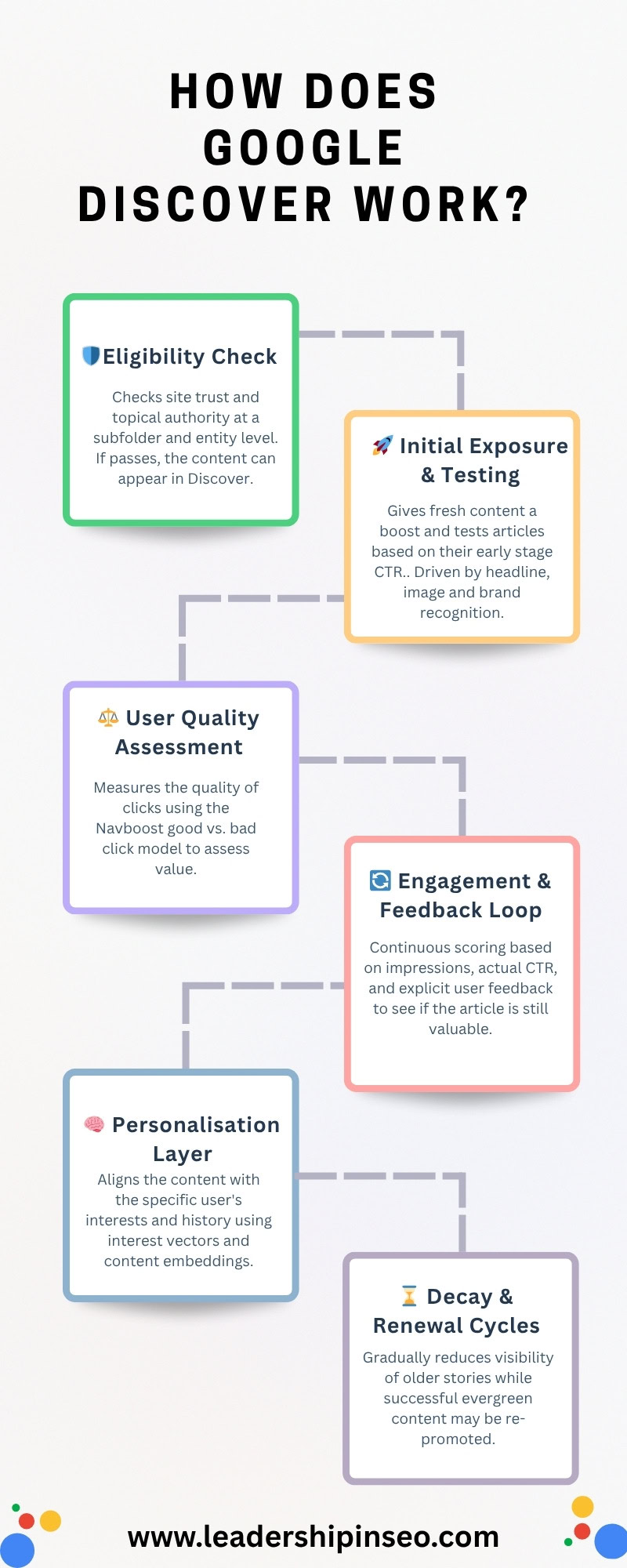 Image Credit: Harry Clarkson-Bennett
Image Credit: Harry Clarkson-BennettGoogle’s Discover Guidelines
This section is boring, and Google’s guidelines around eligibility are exceptionally vague:
- Content is automatically eligible to appear in Discover if it is indexed by Google and meets Discover’s content policies.
- Any kind of dangerous, spammy, deceptive, or violent/vulgar content gets filtered out.
“…Discover makes use of many of the same signals and systems used by Search to determine what is… helpful, reliable, people-first content.”
Then they give some solid, albeit beige advice around quality titles – clicky, not baity as John Shehata would say. Ensuring your featured image is at least 1200px wide and creating timely, value-added content.
But we can do better.
Discover’s Six-Part Content Pipeline
From cradle to grave, let’s review exactly how your content does or, in most cases, doesn’t appear in Discover. As always, remembering I have made these clusters up, albeit based on real Google proxies from the Google leak.
- Eligibility check and baseline filtering.
- Initial exposure and testing.
- User quality assessment.
- Engagement and feedback loop.
- Personalization layer.
- Decay and renewal cycles.
Eligibility And Baseline Filtering
For starters, your site has to be eligible for Google Discover. This means you are seen as a “trusted source” on the topic, and you have a low enough SPAM score that the threshold isn’t triggered.
There are three primary…
Source link
Disclaimer
We strive to uphold the highest ethical standards in all of our reporting and coverage. We blogs.grocliq.com want to be transparent with our readers about any potential conflicts of interest that may arise in our work. It’s possible that some of the investors we feature may have connections to other businesses, including competitors or companies we write about. However, we want to assure our readers that this will not have any impact on the integrity or impartiality of our reporting. We are committed to delivering accurate, unbiased news and information to our audience, and we will continue to uphold our ethics and principles in all of our work. Thank you for your trust and support.
Website Upgradation is going on for any glitch kindly connect at [email protected]